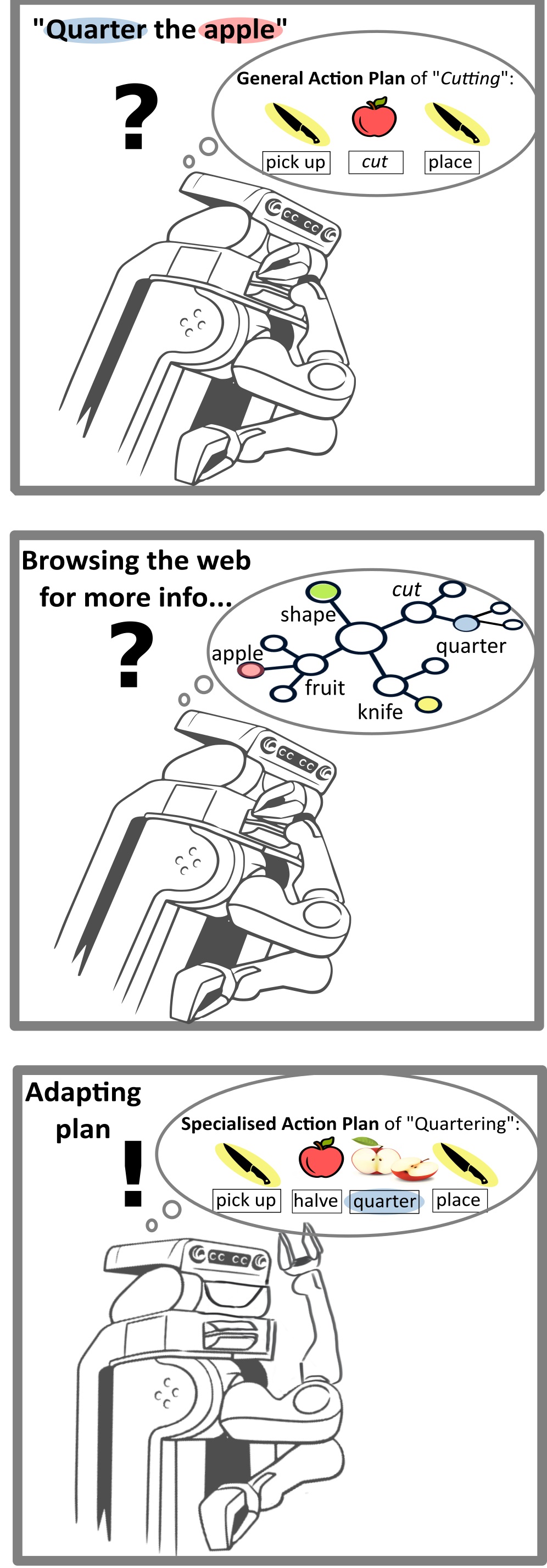
Gathering and Linking Web Knowledge
To support robotic agents in executing variations of Cutting on different fruits and vegetables, we collect two types of knowledge in our knowledge graph: action and object knowledge. Both kinds of knowledge need to be linked to enable task execution as explained here.
Action Knowledge
The action knowledge covers all properties of a specific manipulation action that are necessary for successfully completing the action and is thus also influenced by the participating objects. In general we rely on SOMA1 and its upper ontology DUL2 to model agent participation in events as well as roles objects play during events and how events effect objects.
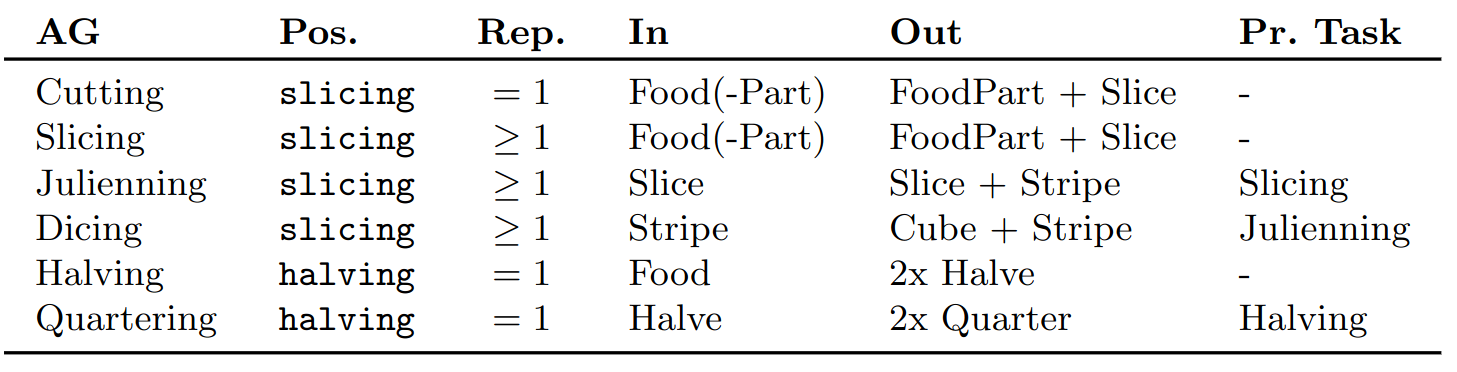
For executing Cutting actions and its variants, we first collect synonyms and hyponyms for Cutting using WordNet3, VerbNet4 and FrameNet5. After filtering these verbs regarding their relevance for the cooking domain using our WikiHow Analysis Tool, we propose to divide them into action groups with similar motion patterns. Based on our observations in WikiHow data and cooking videos, we differentiate between these tasks in three parameters:
- position: Where should the robot place its cutting tool?
- repetitions: How many cuts should the robot perform?
- input: What shape or part of the food is provided for the action?
- output: What shape or part is the result of the action executtion?
- prior task: Does the robot need to execute a specific action group beforehand?
Based on the remaining 14 words, we created the following 6 action groups:
Object Knowledge
As the name suggests, object knowledge covers all relevant information about the objects involved in the task execution (e.g. tools, containers, targets). Of course, the relevance of each piece of information depends on the task to be executed. So, for the task of ”Cutting an apple", the apple’s size or anatomical structure is relevant, but whether it is biodegradable or not is irrelevant
For the target group of fruits & vegetables, we gather the following information in our knowledge graph:
- food classes (e.g. stone fruit or citrus fruit)
- fruits and vegetables
- anatomical parts
- edibility of the anatomical parts
- tool to remove the anatomical parts
We gather these information from structured sources like FoodOn6 and the PlantOntology7, but also from unstructured sources like Recipe1M+8 or wikihow.
In total, the knowledge graph contains:
- 6 food classes
- 18 fruits & 1 vegetable
- 4 anatomical parts (core, peel, stem, shell)
- 3 edibility classes (edible, should be avoided, must be avoided)
- 5 tools (nutcracker, knife, spoon, peeler, hand)
Knowledge Linking
After collecting the aforementioned action and object knowledge, this knowledge needs to be linked in our knowledge graph, so that a robot can infer the correct tool to use for a given task or the correct object to cut. We set both kinds of knowledge in relation through dispositions and affordances, as visualised below for an apple:

In general, a disposition describes the property of an object, thereby enabling an agent to perform a certain task9 as in a knife can be used for cutting, whereas an affordance describes what an object or the environment offers an agent10 as in an apple affords to be cut. Both concepts are set in relation by stating that dispositions allow objects to participate in events, realising affordances that are more abstract descriptions of dispositions1. In our concrete knowledge graph, this is done by using the affordsTask, affordsTrigger and hasDisposition relations introduced in the SOMA ontology1.
WikiHow Analysis Tool
To gather additional knowledge about manipulation actions and their associated verbs, we developed a tool analysing a WikiHow corpus11. The goal is to better the understanding of manipulation verbs and their parameterization for different objects, goals and environments. The tool uses basic NLP techniques like Part-of-Speech Tagging and Coreference Resolution from the Stanford CoreNLP Toolkit12 to extract verb frames.
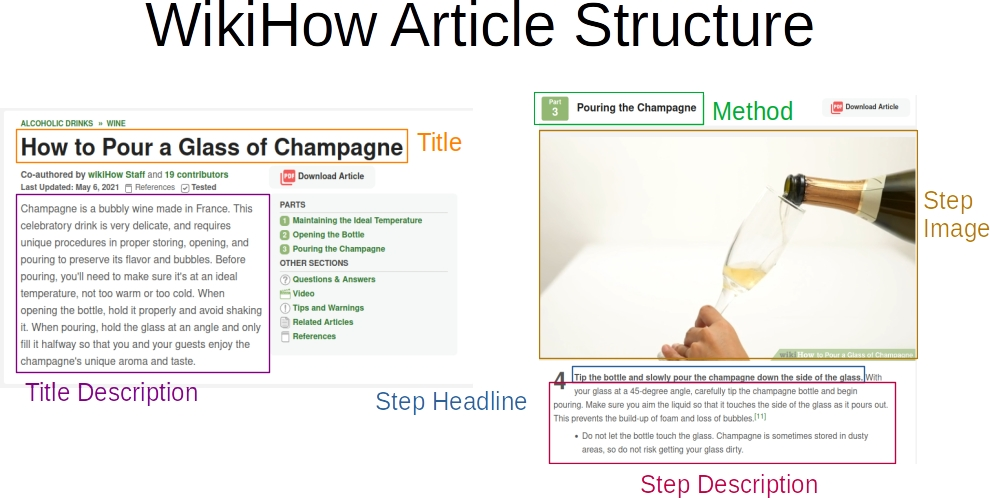
The WikiHow articles analysed by our tool are structured in the following way:
Action Verb Frames
For the current search target, the tool extracts a verb frame. The structure of each frame is manually set for different action groups based on example data from the corpus. Currently, frames for the verb groups centered around Cutting and Pouring are available:
- Cutting Structure:
(Verb, Target, Preposition, Shape) - Cutting Example:
(dice, 1 sweet potato, into, squares) - Pouring Structure:
(Verb, Object, Preposition, Target Location) - Pouring Example:
(pour, the brown sugar, into, the bowl)
In general, a frame is filled with content from a single sentence found in a step description. For the extraction, we use POS Tagging to find the preposition and extract the other two frame elements based on their location in the sentence in relation to the verb and the preposition.
Extracting Verb Occurrences
One current use case for the analysis tool is counting the occurrences of specific synonyms / hyponyms for the representative word for a specific group. We gather these synonyms and hyponyms using WordNet13, VerbNet14 and Thesaurus. In a first step, we manually filter these verbs to only include verbs relevant for the household / cooking domain. Afterwards we count the number of occurrences in the different parts of a WikiHow article. The exemplary result for the Cutting verb group can be seen below:
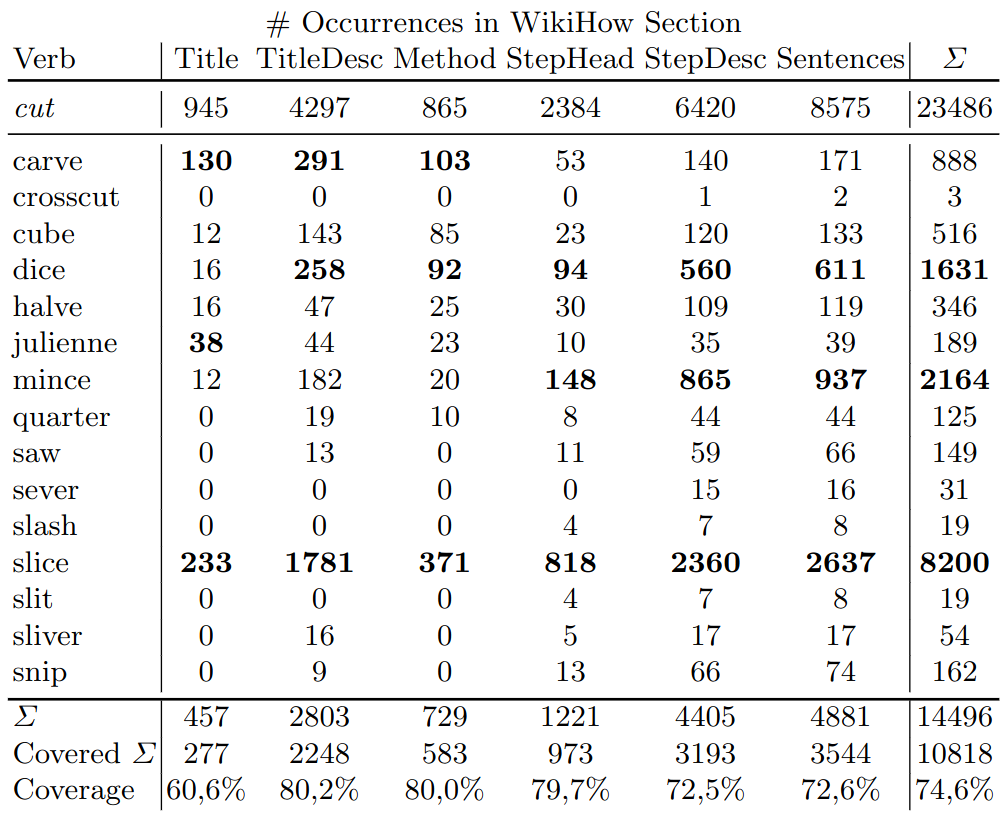
In the table, the three verbs with the most occurrences per column (apart from cut) were marked in bold. In our ontology, we currently cover slice, dice, halve, quarter and cube. With this knowledge, the relevance of different hyponyms for the application domain can be assessed.
References
D. Beßler et al., ‘Foundations of the Socio-physical Model of Activities (SOMA) for Autonomous Robotic Agents’, in Formal Ontology in Information Systems, vol. 344, IOS Press, 2022, pp. 159–174. Accessed: Jul. 25, 2022. doi: 10.3233/FAIA210379. ↩︎ ↩︎ ↩︎
V. Presutti and A. Gangemi, ‘Dolce+ D&S Ultralite and its main ontology design patterns’, in Ontology Engineering with Ontology Design Patterns: Foundations and Applications, P. Hitzler, A. Gangemi, K. Janowicz, A. Krisnadhi, and V. Presutti, Eds. AKA GmbH Berlin, 2016, pp. 81–103. ↩︎
G. A. Miller, ‘WordNet: A Lexical Database for English’, Communications of the ACM, vol. 38, no. 11, pp. 39–41, 1995, doi: 10.1145/219717.219748. ↩︎
K. K. Schuler, ‘VerbNet: A broad-coverage, comprehensive verb lexicon’, PhD Thesis, University of Pennsylvania, 2005. ↩︎
C. F. Baker, C. J. Fillmore, and J. B. Lowe, ‘The Berkeley FrameNet Project’, in Proceedings of the 36th annual meeting on Association for Computational Linguistics -, Montreal, Quebec, Canada: Association for Computational Linguistics, 1998, p. 86. doi: 10.3115/980845.980860. ↩︎
D. M. Dooley et al., ‘FoodOn: a harmonized food ontology to increase global food traceability, quality control and data integration’, npj Sci Food, vol. 2, no. 1, Art. no. 1, Dec. 2018, doi: 10.1038/s41538-018-0032-6. ↩︎
P. Jaiswal et al., ‘Plant Ontology (PO): a Controlled Vocabulary of Plant Structures and Growth Stages’, Comparative and Functional Genomics, vol. 6, no. 7–8, pp. 388–397, 2005, doi: 10.1002/cfg.496. ↩︎
J. Marín et al., ‘Recipe1M+: A Dataset for Learning Cross-Modal Embeddings for Cooking Recipes and Food Images’, IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 1, pp. 187–203, Jan. 2021, doi: 10.1109/TPAMI.2019.2927476. ↩︎
M. T. Turvey, ‘Ecological foundations of cognition: Invariants of perception and action.’, in Cognition: Conceptual and methodological issues., H. L. Pick, P. W. van den Broek, and D. C. Knill, Eds. Washington: American Psychological Association, 1992, pp. 85–117. doi: 10.1037/10564-004. ↩︎
M. H. Bornstein and J. J. Gibson, ‘The Ecological Approach to Visual Perception’, The Journal of Aesthetics and Art Criticism, vol. 39, no. 2, p. 203, 1980, doi: 10.2307/429816. ↩︎
L. Zhang, Q. Lyu, and C. Callison-Burch, ‘Reasoning about Goals, Steps, and Temporal Ordering with WikiHow’, in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online: Association for Computational Linguistics, 2020, pp. 4630–4639. doi: 10.18653/v1/2020.emnlp-main.374. ↩︎
C. D. Manning, M. Surdeanu, J. Bauer, J. Finkel, S. J. Bethard, and D. McClosky, ‘The Stanford CoreNLP Natural Language Processing Toolkit’, in Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, 2014, pp. 55–60. Online ↩︎
G. A. Miller, ‘WordNet: A Lexical Database for English’, Communications of the ACM, vol. 38, no. 11, pp. 39–41, 1995, doi: 10.1145/219717.219748. ↩︎
K. K. Schuler, ‘VerbNet: A broad-coverage, comprehensive verb lexicon’, PhD Thesis, University of Pennsylvania, 2005. ↩︎